
Google 提供的試算表很好用又免費,很多人拿來做自己系統的運算,如果今天有個表格欄位是要填網頁上的某個文字,每次都要自己手動填是不是很麻煩,不用另外寫程式(script),只要學會 IMPORTXML 和 REGEXEXTRACT 兩個函式,就可以完成這個需求。
以下用抓網頁上的報價這個情境當作範例,帶大家走一次。我們想要抓 https://www.f2pool.com/help 上面乙太幣的24小時理論收益(下圖紅字處)。

先使用 IMPORTXML 函式
利用 IMPORTXML,可以抓網頁上指定的區塊。- 第一個參數要填網址,填上 https://www.f2pool.com/help
- 第二個參數要填 XPath 代表某個網頁區塊在 HTML 裡的位置(往下看有教你如何用 Chrome 取得 XPath),在此我們填上 //*[@id='miner-overview']/div/table/tbody/tr[6]/td[5]/strong[1]
- 使用 Chrome 選取要的文字,右鍵按檢查就會跳出開發者主控台,它會跳到該文字在 HTML 上的位置。
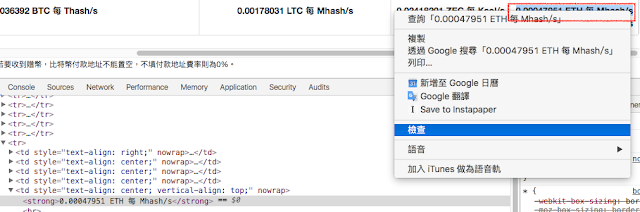
- 開發者主控台選取 HTML 上的位置,右鍵按 Copy > Copy XPath 就能取得 XPath。這邊取得為 //*[@id="miner-overview"]/div/table/tbody/tr[6]/td[5]/strong[1]
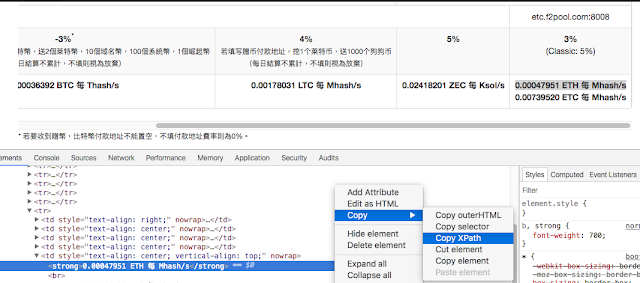
- 把剛剛取得的 XPath 裡頭的雙引號改成單引號,要不然函式會出錯。
上述完成後,我們可以看到試算表已經正確顯示了“0.00047846 ETH 每 Mhash/s”這個字串。

使用 REGEXEXTRACT 函式
利用 REGEXEXTRACT,可以從字串中擷取出我們想要的部分。- 第一個參數填上字串或是表格,這邊我們填上表格。
- 第二個參數填上正規運算式,這邊我們填上 \d+.\d+ ,白話就是找出這個字串中有小數點的數字。
- 推薦使用 http://regexr.com/,可以直接驗證比對的結果。

上述完成後,我們可以看到試算表已經正確顯示了“0.00047846”這個字串。

寫在最後
上述方法碰到一些用 JavaScript 動態更新的網頁上會失效。這做法並不會一直更新,而是會暫存這結果約兩個小時才會在更新,如果想要進一步做到定期更新的話,就需要利用 Google App Script 去定期更新這張試算表,這篇有破臉書100個喜歡再來花時間介紹好了。









2 則回應:
請問幣託買價擷取
=IMPORTXML("https://www.bitoex.com/charts?locale=zh-tw","/html/body/div[3]/div[1]/div[1]/h4/span")
這樣對嗎?
為什麼一直出現N/A
感謝解惑@@"
謝謝,很詳盡的教學,不過我也遇到部分網站會抓到N/A的現象.